Designing an AI-Native SDLC
Introduction
This is a point-in-time snapshot of my evolving jouney with agent-protocols.
Traditional SDLCs are too slow for AI, and letting agents write code without a rigid framework is a fast track to architectural spaghetti. My current setup shifts heavily toward Dual-Track Agile. This ensures that we are continuously planning the next sprint while the current one is being built. By leveraging a highly automated pipeline that combines human product vision, deterministic scaffolding scripts, and parallel AI agent orchestration, we cut down on idle time and keep the architecture from drifting. Let’s walk through how this workflow operates from end to end.
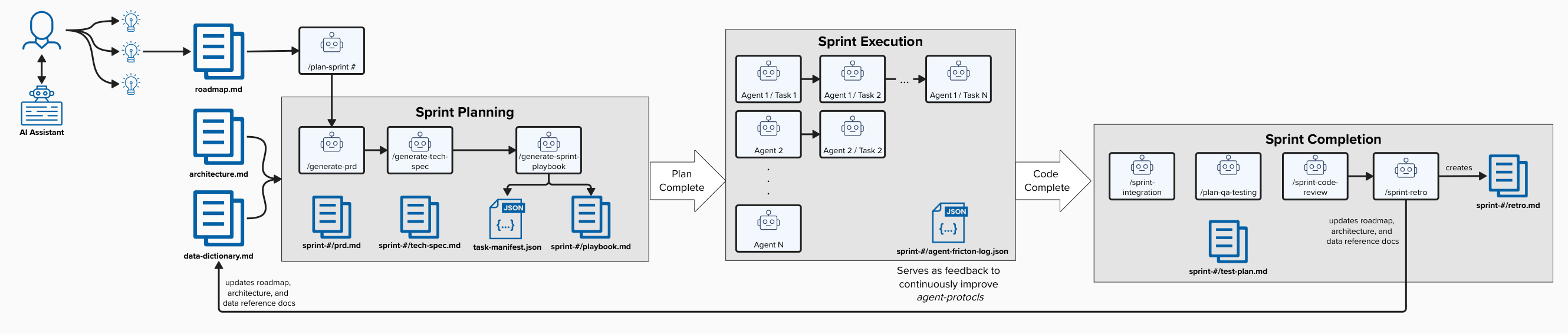
Key Concepts
The workflow is broken down into three distinct phases to provide a structured hand-off between human intelligence and AI execution.
Phase 1: Product Strategy (Manual w/ AI Assistance)
Before any autonomous coding begins, the “North Star” must be defined. A human Product Manager (assisted by an AI thinking partner) manages operations inside the docs/roadmap.md file.
- Roadmap Management: Features are categorized into future horizons (Now, Next, Later).
- Goal Alignment: High-level acceptance criteria boundaries are defined so downstream workflows understand the “definition of done.”
- Initiation: The human operator starts the automated cycle by running the
/plan-sprintcommand.
Phase 2: Sprint Planning (Agentic)
Once the human commands the start of planning, the agentic pipeline takes over. It performs a deterministic crawl of project documentation (such as architecture.md and data-dictionary.md) to build a structured execution plan. We generate three critical artifacts sequentially:
- /generate-prd: Translates the sprint definition in the roadmap into a strict Product Requirements Document (PRD) focusing on User Stories and Acceptance Criteria.
- /generate-tech-spec: Drafts an explicit Technical Specification mapping out Turso/Drizzle schema changes and Hono API routes.
- /generate-sprint-playbook: Translates the PRD and Tech Spec into a concrete
task-manifest.jsonand renders a human-readable Sprint Playbook.
This level of documentation serves two purposes. First, it allows for a quick human sanity check and ensures that the AI agents have a clear, unambiguous map of what needs to be built. Second, it serves as a live project record that tracks every decision and task completion.
Phase 3: Sprint Execution & Closure (Manual + Agentic)
With the playbook.md generated, the engineer shifts into orchestration mode. Whether you’re orchestrating this in an Agentic IDE like Antigravity or using a custom CLI wrapper, the process involves “loading” the playbook to give the manager agent its marching orders.
- Sequential & Concurrent Execution: Agents execute foundational database schema and API route changes sequentially. Once the foundation is locked, the swarm tackles frontend components, QA automation, and documentation in parallel.
- Live Auto-Tracking: Agents autonomously update the playbook state (
- [x]) in real-time, providing a live dashboard of sprint progress. - Observability & Feedback Loop: This is where things get real. In theory, agents follow the
task-manifest.jsonperfectly. In reality? They hit undocumented APIs or hallucinate schema changes and spin their wheels. Recently, I watched an agent burn through a context window trying to resolve a dependency conflict that a human would have flagged instantly. That’s exactly why theagent-friction-log.jsonis the most critical artifact here—it’s the feedback loop that tells us where our human strategy failed the agentic execution.
Every sprint finishes with a strict closing routine to ensure we don’t merge chaos into the main branch:
- /sprint-integration: Sequentially merges feature branches into the sprint branch via
--no-ff. - /plan-qa-testing: Refreshes test data and runs the full suite of comprehensive tests.
- /sprint-code-review: Scans all sprint diffs for security, coupling, and architectural drift.
- /sprint-retro: Captures lessons learned, updates global architectures, and permanently seals the sprint logs.
Conclusion
By orchestrating your SDLC using this dual-track, agentic approach, you remove the friction of disjointed hand-offs and stale documentation. It forces a clean separation of concerns: humans define the “what” and “why,” while AI agents meticulously handle the “how.” Ultimately, the documentation itself transforms into the live control panel for the entire engineering swarm.