The Epic-Centric Agentic SDLC: A Four-Step Framework for Shipping Software in 2026
Introduction
Most teams using AI coding assistants are still running a 2019 process with a 2026 tool. Daily stand-ups, two-week planning marathons, human-authored Jira grooming. Then an agent is asked to “help” inside that legacy scaffolding and the win is measured in faster autocomplete. That is not an agentic SDLC.
This post documents Version 5 of my process, one designed from the ground up for agentic execution. I’ve continued iterating on my agentic SDLC (agent-protocols), and the shape that has emerged is simple enough to fit on a whiteboard and robust enough to ship real software. It boils down to four stages executed against a single GitHub Epic, with humans entering only at the boundaries that still require taste and judgment.
The diagram below is not a hypothetical. It’s the loop I have been using to develop production software. This post expands on each step, why it is shaped this way, and what it replaces in the traditional lifecycle.
Key Concepts
Three architectural commitments underpin every step that follows.
GitHub is the SSOT
Before the four steps, the non-negotiable architectural decision: GitHub is the single source of truth. This goes for code, issues, labels, etc.
This matters because agents need a durable, queryable, multi-writer substrate to coordinate against. GitHub already is that substrate: it has auth, audit, permissions, an API, webhooks, and a UI your humans already use. Every ticket becomes both a unit of work and a unit of state. An agent writes a comment; a human reads it. A human edits a label; an agent reacts. The loop closes without glue code.
Everything below assumes that substrate.
Humans own intent; agents own execution
The second commitment is a division of labor. Humans write the Epic, approve the risk::high gates, and sign off on the release. Agents do everything in between — planning, decomposition, implementation, testing, auditing, documentation. The protocol is careful about where those two domains meet, because every unnecessary human touchpoint is a latency spike and every skipped gate is a production incident waiting to happen.
Context is engineered, not improvised
The third commitment is that prompts are treated as deliverables. Every agent run is hydrated with a precise, bounded context bundle (personas, skills, hierarchy, branch state, task instructions) assembled by code rather than by a developer copy-pasting into a chat window. This is what makes the loop reproducible.
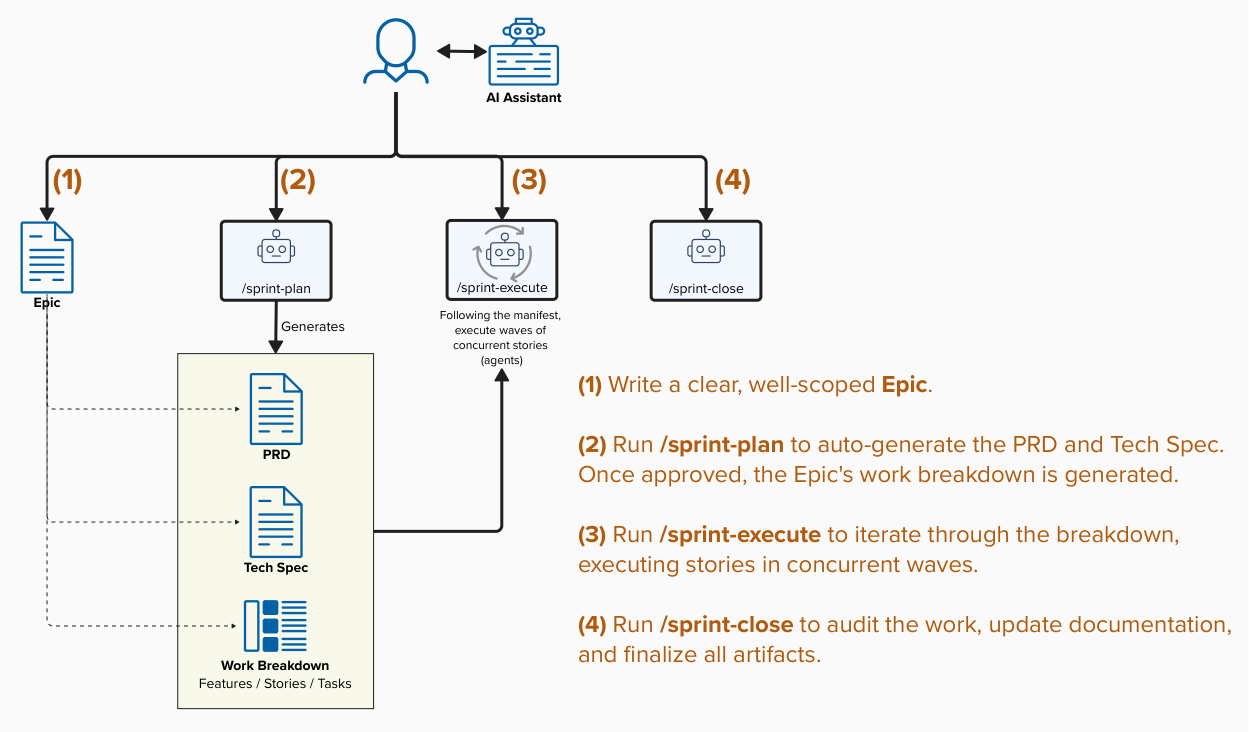
Step 1 — Write a clear, well-scoped Epic (Human w/ AI Assistant)
The entire pipeline is triggered by one artifact: a GitHub Issue labeled type::epic, written in plain English by a human who actually understands the business and product. This is where the product discipline earns its keep.
This is not a placeholder. This is the entire product input. An Epic that says “improve checkout” produces garbage. An Epic that says “reduce cart abandonment on mobile Safari by shortening the payment step to one tap using Apple Pay when available, with a fallback to the existing flow, measured by weekly conversion delta” produces an actionable plan.
Good Epics share three properties:
- A clear why. The business outcome, not the implementation. Agents will invent the implementation.
- A hard scope boundary. What is explicitly not in this Epic. Without it, the planner will happily scope-creep into adjacent features.
- Success criteria you could actually check. “Checkout feels faster” is not checkable. “P75 checkout time drops below 4 seconds” is.
Step 2 — /sprint-plan (Agentic)
Once the Epic is written and approved, a human runs /sprint-plan [EPIC_ID]. From that moment, planning is autonomous. Two agents run in sequence:
The Epic Planner reads the Epic body alongside the project’s reference documentation (e.g. architecture.md, decisions.md, patterns.md, style-guide.md, etc.) and generates two linked child issues:
- A PRD (
context::prd) — the formal product specification: actors, acceptance criteria, edge cases, non-goals. - A Tech Spec (
context::tech-spec) — the implementation plan: components, data flows, API contracts, migration strategy, risk callouts.
The Ticket Decomposer then recursively explodes the spec into a four-tier hierarchy:
Epic
├── Feature (a shippable slice)
│ ├── Story (a cohesive group of tasks)
│ │ ├── Task (atomic agent work unit, with subtasks)
│ │ └── Task
│ └── Story
└── FeatureEach Task is stamped with the metadata the execution engine needs: the persona that should run it (engineer, qa-engineer, architect), the recommended model tier (fast, standard, high), the estimated files it will touch, and the agent prompt itself. Dependencies are wired using GitHub’s native blocked by #NNN sub-issue links, which means the dependency graph is queryable as data, not parsed out of markdown.
Why bother with a formal breakdown when an agent could “just figure it out”? Three reasons:
- Parallelism needs a DAG Directed Acyclic Graph. A map of tasks and their dependencies with no cycles, so the system always knows which work can run in parallel and which must wait for something upstream to finish first. . You cannot safely run five agents concurrently without an explicit dependency graph. The breakdown is the graph.
- Humans need to skim. A product lead should be able to scroll the Feature list in five minutes and catch “that’s not what I meant.” Before any code is written.
- Replans are cheap. If the spec changes, you re-run the decomposer on the changed subtree. You don’t throw out the Epic.
This phase replaces roughly days or weeks of traditional sprint planning and grooming. It runs in minutes.
Step 3 — /sprint-execute (Agentic)
Based on the planning above, a manifest specifying Waves of Stories will be generated. A Wave is a set of Stories with no inter-dependencies, allowing them to be executed concurrently by independent agents. Waves are executed sequentially, while Stories within a Wave run in parallel.
This is where the work gets done: /sprint-execute [STORY_ID].
Story-level branching, not task-level
A subtle but load-bearing design choice: all Tasks inside a Story execute sequentially on a shared Story branch (story/epic-42/checkout-apple-pay), not on one branch per Task. This trades a little parallelism for a massive reduction in merge conflicts, because related changes converge on the same slice of code. If you’ve ever watched five agents race to rename the same utility in five different PRs, you understand why this matters.
The Story execution lifecycle
When an operator kicks off a Story, an automated lifecycle takes over:
- Initialization — the Epic base branch is synced with
main, the Story branch is created or checked out, and all child Tasks transition toagent::executing. - Task implementation — the agent executes each Task sequentially on the shared Story branch, committing after each Task, running lint/typecheck/test locally as it goes.
- Closure — shift-left validation runs (lint, format, test), the Story branch merges into the Epic base branch, Task status cascades up to Story and Feature, and the Story branch is cleaned up.
Context hydration
Every agent run begins with a context hydrator An automated step that gathers everything an agent needs into one self-contained prompt: its persona, the relevant protocols and skills, the full work hierarchy, and the current branch state, so the agent starts with full situational awareness. that assembles a self-contained prompt: the universal agent protocol, the persona and skill directives for this Task, the full hierarchy (Story → Feature → Epic → PRD → Tech Spec), the current state of the Story branch, and the Task’s own instructions and subtask checklist. The agent doesn’t have to “figure out what’s going on”, it is handed exactly the context the task requires, nothing more.
This is the difference between “ask an AI to code” and “run an engineering org where AI does the coding.” Context is not an afterthought; it is inherent.
Real-time state sync
Agents update GitHub in real time as they work:
- Labels move through
agent::ready→agent::executing→agent::review→agent::done. - Subtask checkboxes in the ticket body flip from
- [ ]to- [x]. - Friction events (unexpected errors, ambiguous instructions, repeated failures) post as structured comments on the Task, feeding the protocol-refinement loop.
A human scanning the Epic’s sub-issue tree at any moment can see exactly what’s done, what’s running, and what’s stuck.
HITL gates where they actually matter
Tasks labeled risk::high (e.g., destructive DB mutations, auth changes, public URL changes) are held for explicit human approval This is a HITL (Human-in-the-Loop) gate: a checkpoint where a person must review and approve before the system proceeds, reserved for decisions that are costly or impossible to reverse. before dispatch. The rest run autonomously. This is the correct place for humans: not approving every line of code, but approving the decisions that would be expensive to reverse.
Audit gates built into the lifecycle
Four static-analysis gates fire automatically through the pipeline:
| Gate | When | Runs |
|---|---|---|
| Gate 1 | After Story completion | Content-triggered audits (clean-code, etc.) |
| Gate 2 | Pre-integration | Dependency and DevOps audits |
| Gate 3 | Code-review phase | Full automated audit pass |
| Gate 4 | Sprint close, before Epic → main | Production-readiness gate (audit-sre) |
This is the end-to-end engineering discipline made concrete. Quality, security, and privacy are not a checklist at the end; they are gates the pipeline physically cannot pass without satisfying.
Step 4 — /sprint-close (Agentic with a human sign-off)
Once all Stories in the Epic have merged into the Epic base branch, the closure phase runs. Three bookends execute in order:
/sprint-code-review— a comprehensive review pass using thearchitectpersona and code-quality/security skills. Findings post back to the Epic as structured comments; any High or Critical finding halts for human approval./sprint-retro— the retrospective agent walks the full ticket graph (friction logs, time-to-done, failed audits, HITL interventions) and generates aretro.mdartifact with wins, frictions, and protocol refinements to apply next sprint./sprint-close— merges the Epic branch tomain, validates documentation freshness (architecture.md,decisions.md,ROADMAP.md), bumps the version, tags the release, and closes the Epic issue along with its PRD and Tech Spec context tickets.
The retrospective is the part most teams skip in traditional SDLCs, because by Friday afternoon no one has energy left. In the agentic model, it is free. The data is already on the tickets. The agent just synthesizes it. Over time, the friction log becomes a training corpus for your own protocol. The system literally learns from each Epic how to run the next one better.
What this replaces
Mapping the four steps back to a traditional shop:
| Traditional | Epic-Centric Agentic |
|---|---|
| Two-week planning sprint | /sprint-plan (minutes) |
| Hand-off docs, spec review meetings | PRD + Tech Spec issues auto-generated |
| Ticket grooming | Ticket Decomposer + dependency graph |
| Stand-ups and status decks | Live label state on the Epic sub-issue tree |
| Merge hell at end of sprint | Story-level branching + shift-left validation |
| Ad-hoc QA pass | Four audit gates built into the lifecycle |
| Retro that nobody writes | /sprint-retro runs on ticket telemetry |
| Release checklist in a wiki | /sprint-close enforces it as code |
Conclusion
The four-step Epic-Centric SDLC is what a 2026 software team actually looks like when you take agents seriously. A human writes a clear Epic. An agent plans it. Agents execute it on Story branches with audit gates and real-time state sync. An agent closes it, with a human signing off on anything irreversible.
It is calmer than traditional sprints. It is faster. It is more auditable, because every decision is a ticket and every ticket has a label history. And it is completely consistent with the broader shift toward development focusing more on specifying intent and engineering the system that makes execution safe, not in the middle, where agents now live.
If your team’s sprints still feel like 2019, the gap isn’t a tooling gap. It’s a process gap. Pick a single Epic next week, run it through these four steps, and see what breaks. Whatever breaks is the next thing to build. That is the real SDLC now: continuously refining the protocol that runs the protocol.
The full protocol definitions, agent prompts, personas, skills, and reference docs are open source at agent-protocols on GitHub — fork it, break it, tell me what didn’t work.